Publications
A list of my publications in reverse chronological order.
2026
-
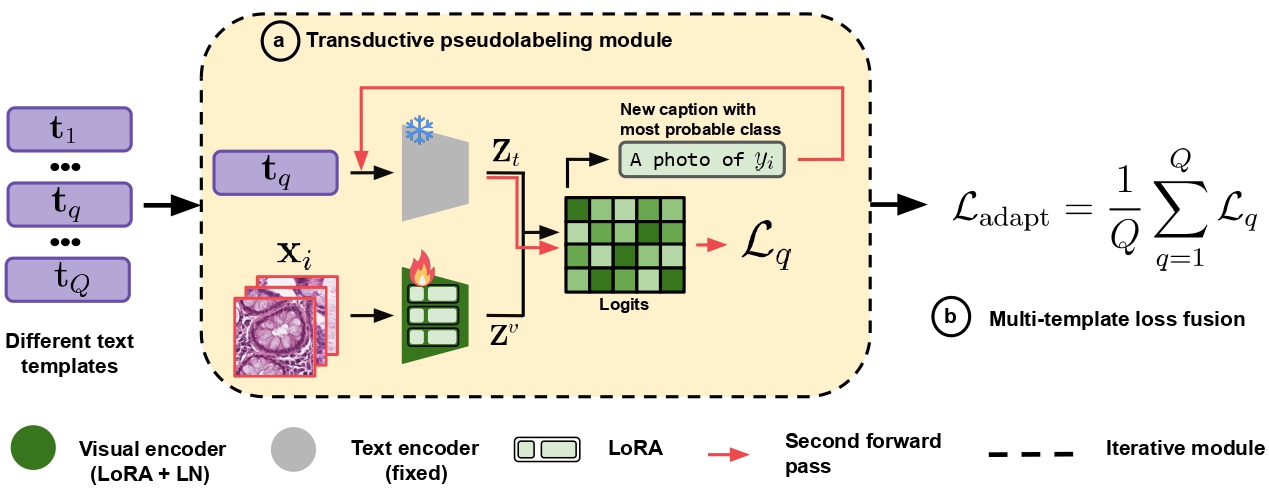 Histopath-C: Towards Realistic Domain Shifts for Histopathology Vision-Language AdaptationMehrdad Noori*, Gustavo Hakim*, David Osowiechi* , more authorsIn WACV , 2026
Histopath-C: Towards Realistic Domain Shifts for Histopathology Vision-Language AdaptationMehrdad Noori*, Gustavo Hakim*, David Osowiechi* , more authorsIn WACV , 2026Medical Vision-language models (VLMs) have shown remarkable performances in various medical imaging domains such as histo\-pathology by leveraging pre-trained, contrastive models that exploit visual and textual information. However, histopathology images may exhibit severe domain shifts, such as staining, contamination, blurring, and noise, which may severely degrade the VLM’s downstream performance. In this work, we introduce Histopath-C, a new benchmark with realistic synthetic corruptions designed to mimic real-world distribution shifts observed in digital histopathology. Our framework dynamically applies corruptions to any available dataset and evaluates Test-Time Adaptation (TTA) mechanisms on the fly. We then propose LATTE, a transductive, low-rank adaptation strategy that exploits multiple text templates, mitigating the sensitivity of histopathology VLMs to diverse text inputs. Our approach outperforms state-of-the-art TTA methods originally designed for natural images across a breadth of histopathology datasets, demonstrating the effectiveness of our proposed design for robust adaptation in histopathology images. Code and data are available at https://github.com/Mehrdad-Noori/Histopath-C.

2025
-
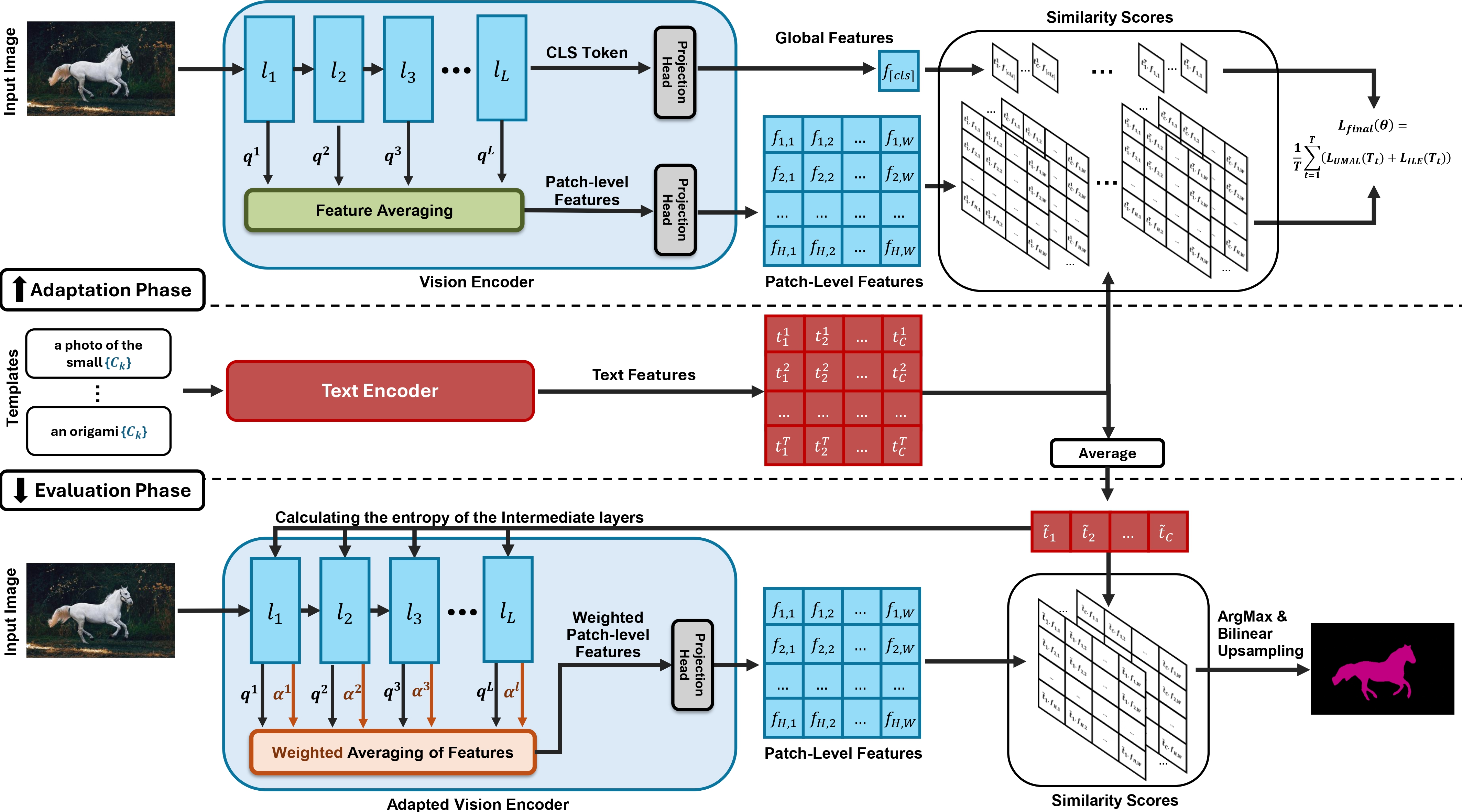 Test-Time Adaptation of Vision-Language Models for Open-Vocabulary Semantic SegmentationMehrdad Noori*, David Osowiechi*, Gustavo Hakim , more authorsIn NeurIPS , 2025
Test-Time Adaptation of Vision-Language Models for Open-Vocabulary Semantic SegmentationMehrdad Noori*, David Osowiechi*, Gustavo Hakim , more authorsIn NeurIPS , 2025Recently, test-time adaptation has attracted wide interest in the context of vision-language models for image classification. However, to the best of our knowledge, the problem is completely overlooked in dense prediction tasks such as Open-Vocabulary Semantic Segmentation (OVSS). In response, we propose a novel TTA method tailored to adapting VLMs for segmentation during test time. Unlike TTA methods for image classification, our Multi-Level and Multi-Prompt (MLMP) entropy minimization integrates features from intermediate vision-encoder layers and is performed with different text-prompt templates at both the global CLS token and local pixel-wise levels. Our approach could be used as plug-and-play for any segmentation network, does not require additional training data or labels, and remains effective even with a single test sample. Furthermore, we introduce a comprehensive OVSS TTA benchmark suite, which integrates a rigorous evaluation protocol, seven segmentation datasets, and 15 common corruptions, with a total of 82 distinct test scenarios, establishing a standardized and comprehensive testbed for future TTA research in open-vocabulary segmentation. Our experiments on this suite demonstrate that our segmentation-tailored method consistently delivers significant gains over direct adoption of TTA classification baselines.
-
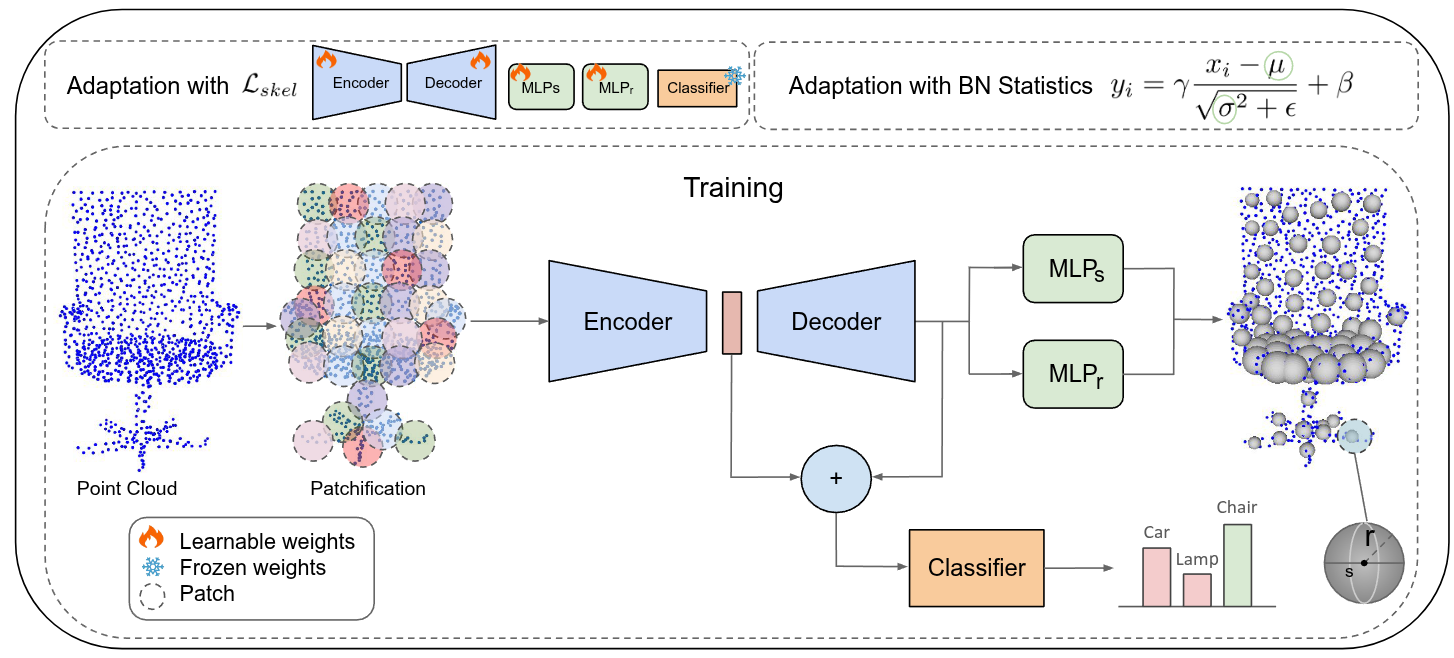 Test-Time Adaptation in Point Clouds: Leveraging Sampling Variation with Weight AveragingAli Bahri, Moslem Yazdanpanah, Sahar Dastani , more authorsIn ICML , 2025
Test-Time Adaptation in Point Clouds: Leveraging Sampling Variation with Weight AveragingAli Bahri, Moslem Yazdanpanah, Sahar Dastani , more authorsIn ICML , 2025Test-Time Training (TTT) has emerged as a promising solution to address distribution shifts in 3D point cloud classification. However, existing methods often rely on computationally expensive backpropagation during adaptation, limiting their applicability in real-world, time-sensitive scenarios. In this paper, we introduce SMART-PC, a skeleton-based framework that enhances resilience to corruptions by leveraging the geometric structure of 3D point clouds. During pre-training, our method predicts skeletal representations, enabling the model to extract robust and meaningful geometric features that are less sensitive to corruptions, thereby improving adaptability to test-time distribution shifts. Unlike prior approaches, SMART-PC achieves real-time adaptation by eliminating backpropagation and updating only BatchNorm statistics, resulting in a lightweight and efficient framework capable of achieving high frame-per-second rates while maintaining superior classification performance. Extensive experiments on benchmark datasets, including ModelNet40-C, ShapeNet-C, and ScanObjectNN-C, demonstrate that SMART-PC achieves state-of-the-art results, outperforming existing methods such as MATE in terms of both accuracy and computational efficiency.
-
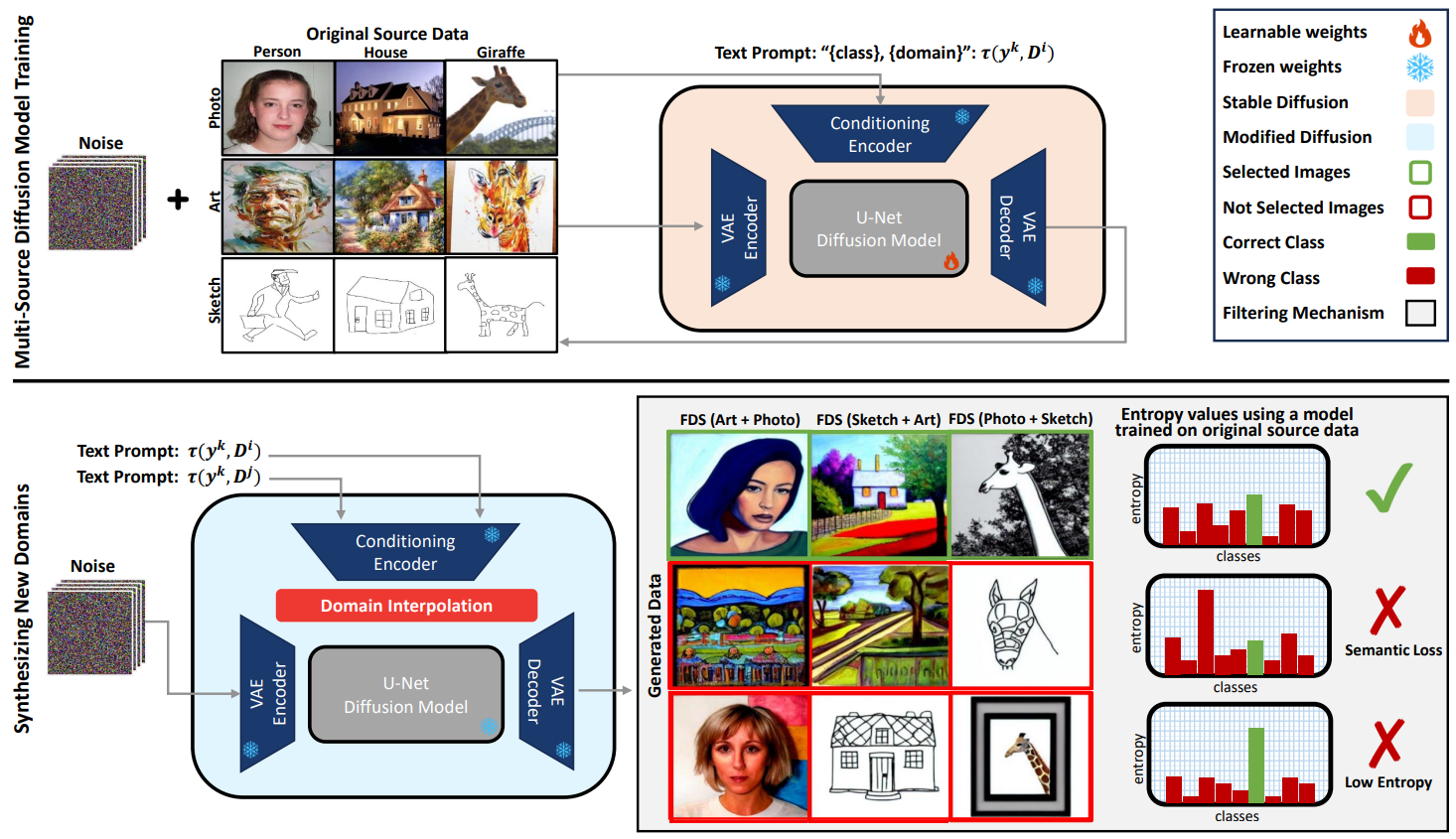 FDS: Feedback-Guided Domain Synthesis with Multi-Source Conditional Diffusion Models for Domain GeneralizationMehrdad Noori, Milad Cheraghalikhani, Ali Bahri , more authorsIn WACV , 2025 - ETS Research Award 🏆
FDS: Feedback-Guided Domain Synthesis with Multi-Source Conditional Diffusion Models for Domain GeneralizationMehrdad Noori, Milad Cheraghalikhani, Ali Bahri , more authorsIn WACV , 2025 - ETS Research Award 🏆Domain Generalization techniques aim to enhance model robustness by simulating novel data distributions during training, typically through various augmentation or stylization strategies. However, these methods frequently suffer from limited control over the diversity of generated images and lack assurance that these images span distinct distributions. To address these challenges, we propose FDS, Feedback-guided Domain Synthesis, a novel strategy that employs diffusion models to synthesize novel, pseudo-domains by training a single model on all source domains and performing domain mixing based on learned features. By incorporating images that pose classification challenges to models trained on original samples, alongside the original dataset, we ensure the generation of a training set that spans a broad distribution spectrum. Our comprehensive evaluations demonstrate that this methodology sets new benchmarks in domain generalization performance across a range of challenging datasets, effectively managing diverse types of domain shifts. The code can be found at: https://github.com/Mehrdad-Noori/FDS.
-
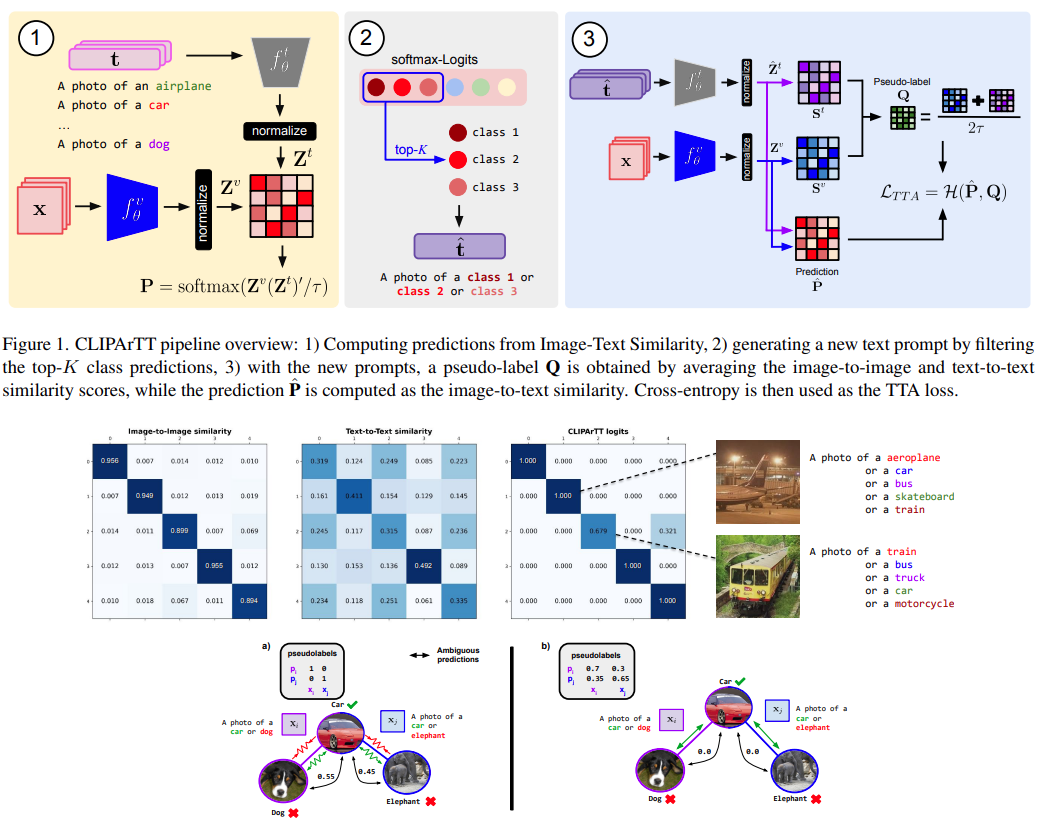 CLIPArTT: Adaptation of CLIP to New Domains at Test TimeGustavo Hakim, David Osowiechi, Mehrdad Noori , more authorsIn WACV , 2025
CLIPArTT: Adaptation of CLIP to New Domains at Test TimeGustavo Hakim, David Osowiechi, Mehrdad Noori , more authorsIn WACV , 2025Pre-trained vision-language models (VLMs), exemplified by CLIP, demonstrate remarkable adaptability across zero-shot classification tasks without additional training. However, their performance diminishes in the presence of domain shifts. In this study, we introduce CLIP Adaptation duRing Test-Time (CLIPArTT), a fully test-time adaptation (TTA) approach for CLIP, which involves automatic text prompts construction during inference for their use as text supervision. Our method employs a unique, minimally invasive text prompt tuning process, wherein multiple predicted classes are aggregated into a single new text prompt, used as \emphpseudo label to re-classify inputs in a transductive manner. Additionally, we pioneer the standardization of TTA benchmarks (e.g., TENT) in the realm of VLMs. Our findings demonstrate that, without requiring additional transformations nor new trainable modules, CLIPArTT enhances performance dynamically across non-corrupted datasets such as CIFAR-100, corrupted datasets like CIFAR-100-C and ImageNet-C, alongside synthetic datasets such as VisDA-C. This research underscores the potential for improving VLMs’ adaptability through novel test-time strategies, offering insights for robust performance across varied datasets and environments.
-
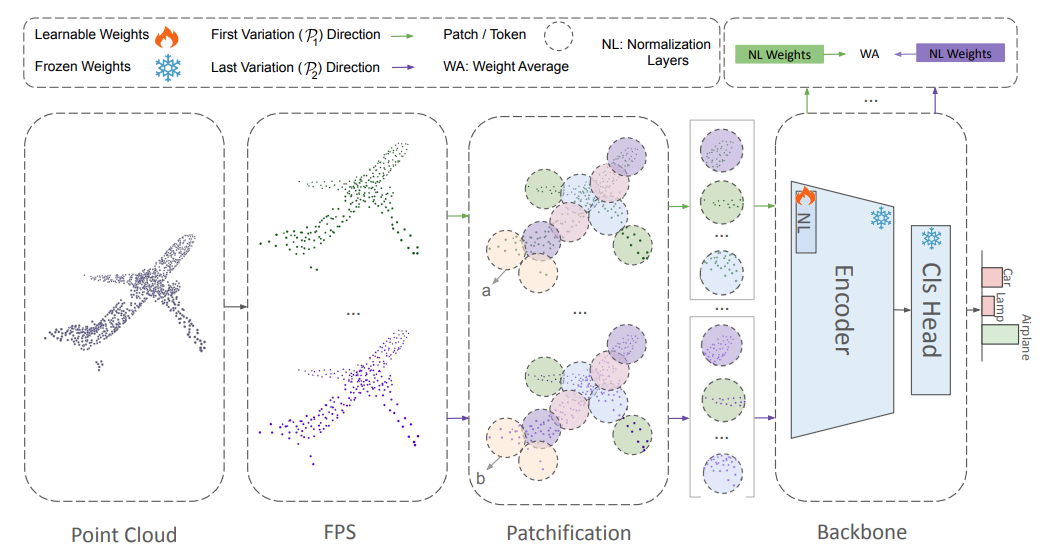 Test-Time Adaptation in Point Clouds: Leveraging Sampling Variation with Weight AveragingAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsIn WACV , 2025 - Oral 🏆
Test-Time Adaptation in Point Clouds: Leveraging Sampling Variation with Weight AveragingAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsIn WACV , 2025 - Oral 🏆Test-Time Adaptation (TTA) addresses distribution shifts during testing by adapting a pretrained model without access to source data. In this work, we propose a novel TTA approach for 3D point cloud classification, combining sampling variation with weight averaging. Our method leverages Farthest Point Sampling (FPS) and K-Nearest Neighbors (KNN) to create multiple point cloud representations, adapting the model for each variation using the TENT algorithm. The final model parameters are obtained by averaging the adapted weights, leading to improved robustness against distribution shifts. Extensive experiments on ModelNet40-C, ShapeNet-C, and ScanObjectNN-C datasets, with different backbones (Point-MAE, Point-Net, DGCNN), demonstrate that our approach consistently outperforms existing methods while maintaining minimal resource overhead. The proposed method effectively enhances model generalization and stability in challenging real-world conditions.
-
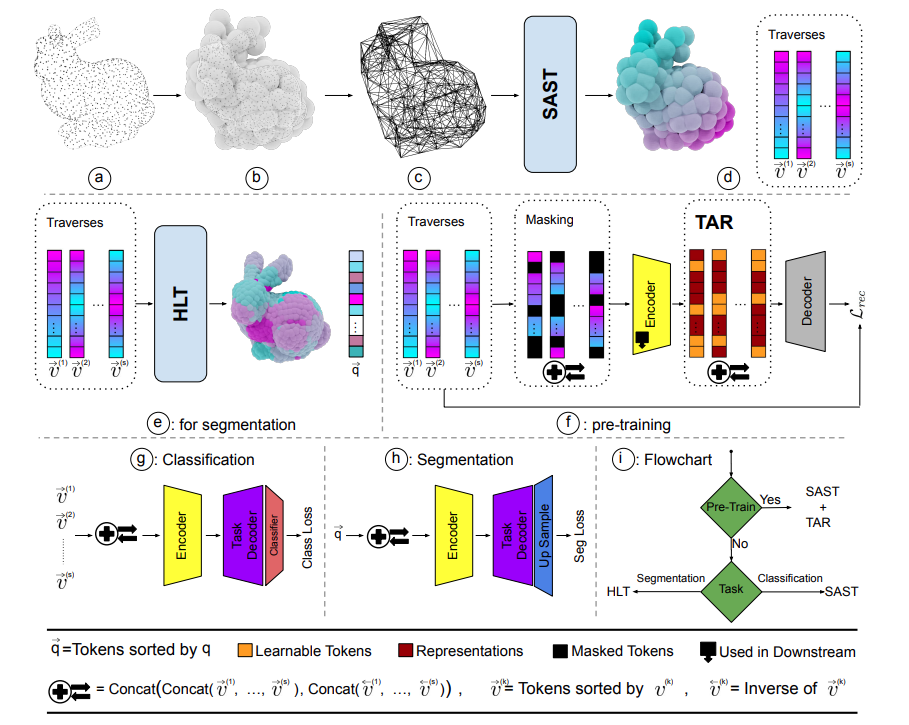 Spectral Informed Mamba for Robust Point Cloud ProcessingAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsIn CVPR , 2025
Spectral Informed Mamba for Robust Point Cloud ProcessingAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsIn CVPR , 2025State space models have shown significant promise in Natural Language Processing (NLP) and, more recently, computer vision. This paper introduces a new methodology leveraging Mamba and Masked Autoencoder networks for point cloud data in both supervised and self-supervised learning. We propose three key contributions to enhance Mamba’s capability in processing complex point cloud structures. First, we exploit the spectrum of a graph Laplacian to capture patch connectivity, defining an isometry-invariant traversal order that is robust to viewpoints and better captures shape manifolds than traditional 3D grid-based traversals. Second, we adapt segmentation via a recursive patch partitioning strategy informed by Laplacian spectral components, allowing finer integration and segment analysis. Third, we address token placement in Masked Autoencoder for Mamba by restoring tokens to their original positions, which preserves essential order and improves learning. Extensive experiments demonstrate the improvements of our approach in classification, segmentation, and few-shot tasks over state-of-the-art baselines.
-
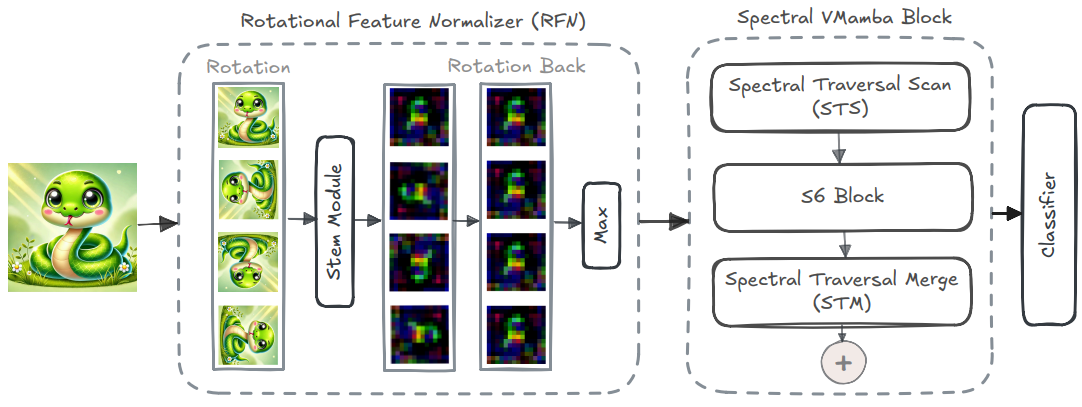 Spectral State Space Model for Rotation-Invariant Visual Representation LearningSahar Dastani, Ali Bahri, Moslem Yazdanpanah , more authorsIn CVPR , 2025
Spectral State Space Model for Rotation-Invariant Visual Representation LearningSahar Dastani, Ali Bahri, Moslem Yazdanpanah , more authorsIn CVPR , 2025State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
-
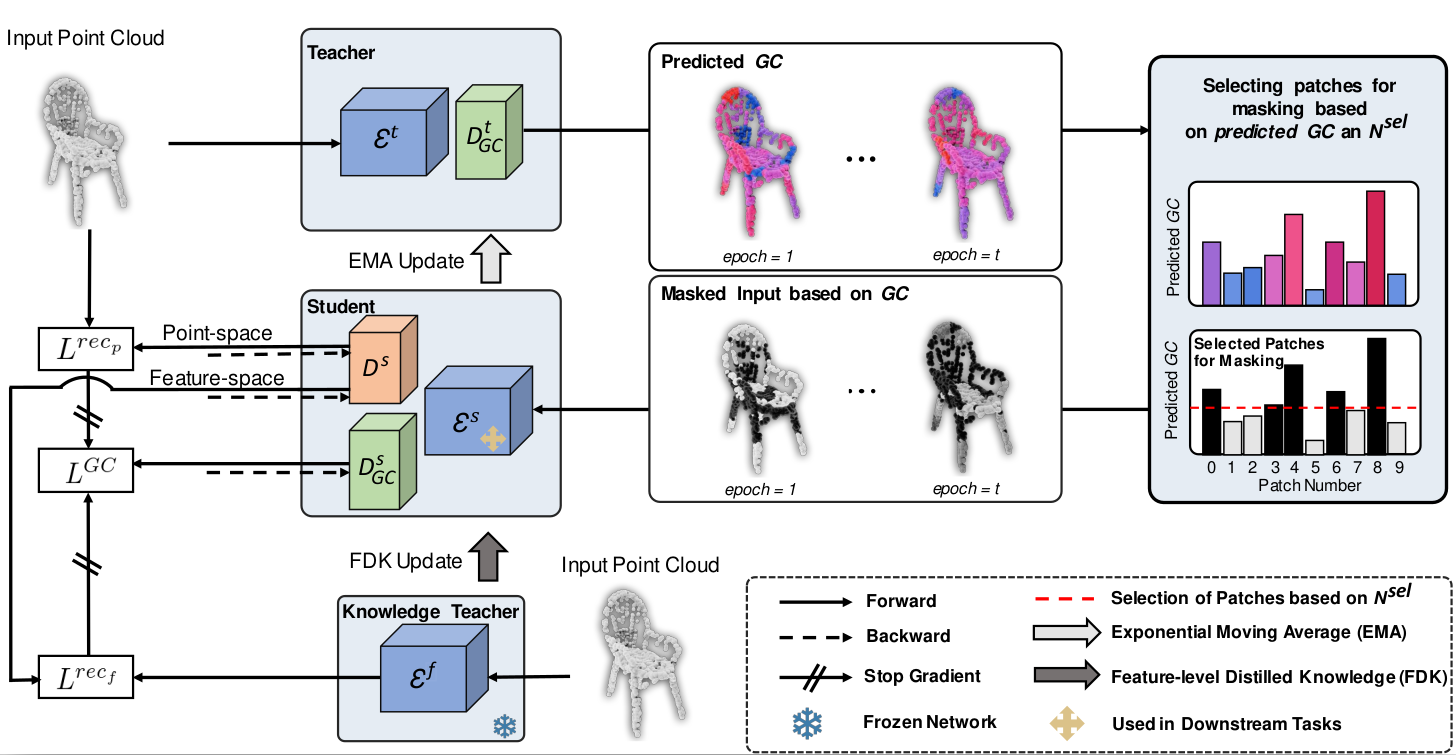 GeoMask3D: Geometrically Informed Mask Selection for Self-Supervised Point Cloud Learning in 3DAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsTransactions on Machine Learning Research, 2025
GeoMask3D: Geometrically Informed Mask Selection for Self-Supervised Point Cloud Learning in 3DAli Bahri, Moslem Yazdanpanah, Mehrdad Noori , more authorsTransactions on Machine Learning Research, 2025We introduce a novel approach to self-supervised learning for point clouds, employing a geometrically informed mask selection strategy called GeoMask3D (GM3D) to boost the efficiency of Masked Auto Encoders (MAE). Unlike the conventional method of random masking, our technique utilizes a teacher-student model to focus on intricate areas within the data, guiding the model’s focus toward regions with higher geometric complexity. This strategy is grounded in the hypothesis that concentrating on harder patches yields a more robust feature representation, as evidenced by the improved performance on downstream tasks. Our method also presents a feature-level knowledge distillation technique designed to guide the prediction of geometric complexity, which utilizes a comprehensive context from feature-level information. Extensive experiments confirm our method’s superiority over State-Of-The-Art (SOTA) baselines, demonstrating marked improvements in classification, segmentation, and few-shot tasks.








2024
-
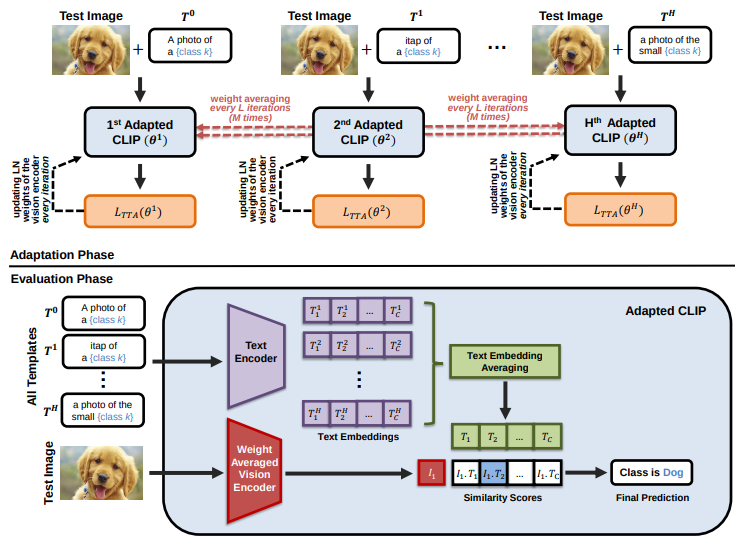 WATT: Weight Average Test Time Adaptation of CLIPDavid Osowiechi*, Mehrdad Noori*, Gustavo Hakim , more authorsIn NeurIPS , 2024
WATT: Weight Average Test Time Adaptation of CLIPDavid Osowiechi*, Mehrdad Noori*, Gustavo Hakim , more authorsIn NeurIPS , 2024Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performances for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a new approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing the overall test performance by aggregating diverse textual cues.Our findings underscore the effectiveness of WATT across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without the need for additional model transformations or trainable modules. Moreover, compared to other TTA methods, our approach can operate effectively with just a single image. The code is available at: https://github.com/Mehrdad-Noori/WATT.
-
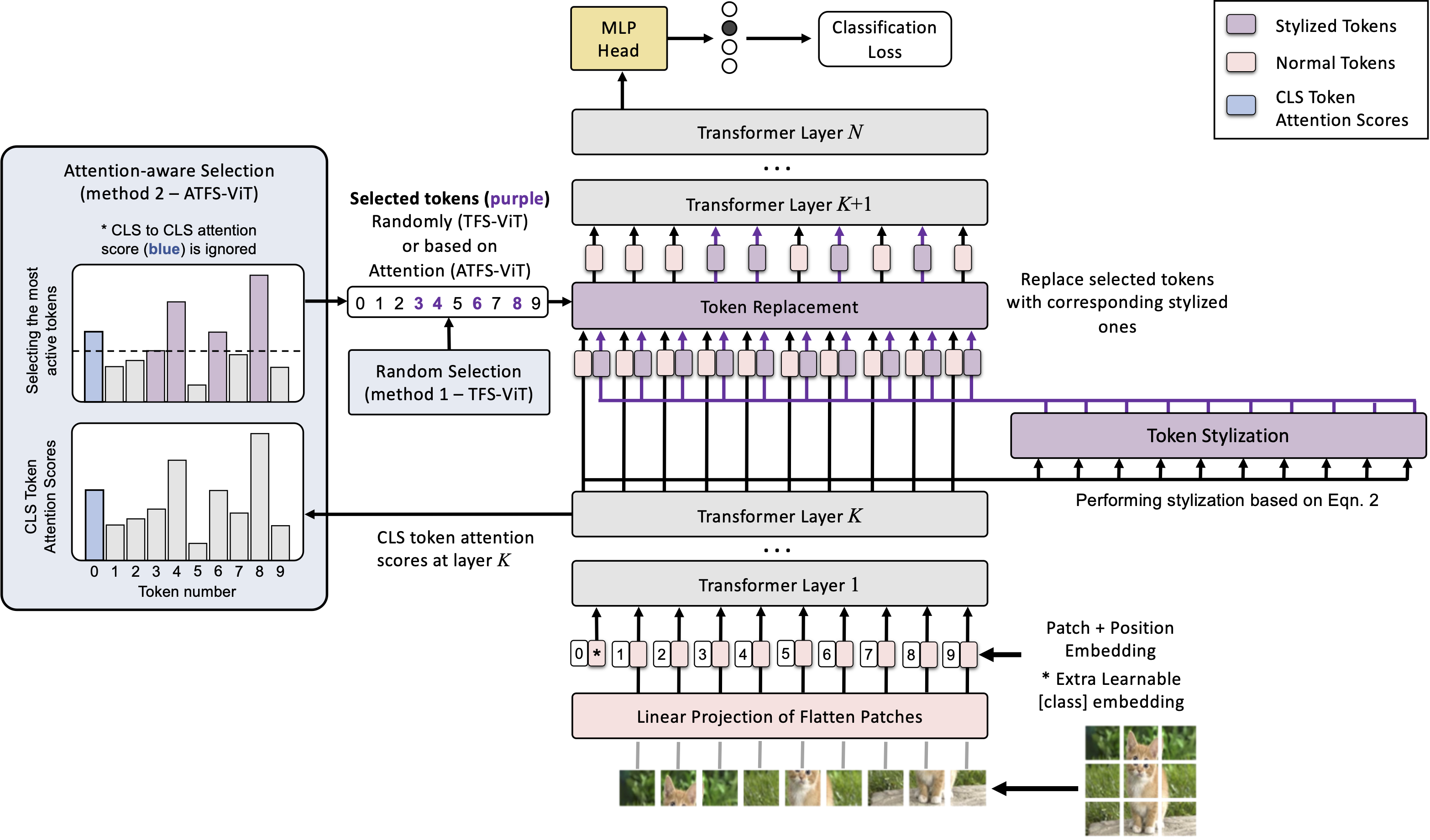 Tfs-vit: Token-level feature stylization for domain generalizationMehrdad Noori, Milad Cheraghalikhani, Ali Bahri , more authorsPattern Recognition, 2024
Tfs-vit: Token-level feature stylization for domain generalizationMehrdad Noori, Milad Cheraghalikhani, Ali Bahri , more authorsPattern Recognition, 2024Standard deep learning models such as convolutional neural networks (CNNs) lack the ability of generalizing to domains which have not been seen during training. This problem is mainly due to the common but often wrong assumption of such models that the source and target data come from the same i.i.d. distribution. Recently, Vision Transformers (ViTs) have shown outstanding performance for a broad range of computer vision tasks. However, very few studies have investigated their ability to generalize to new domains. This paper presents a first Token-level Feature Stylization (TFS-ViT) approach for domain generalization, which improves the performance of ViTs to unseen data by synthesizing new domains. Our approach transforms token features by mixing the normalization statistics of images from different domains. We further improve this approach with a novel strategy for attention-aware stylization, which uses the attention maps of class (CLS) tokens to compute and mix normalization statistics of tokens corresponding to different image regions. The proposed method is flexible to the choice of backbone model and can be easily applied to any ViT-based architecture with a negligible increase in computational complexity. Comprehensive experiments show that our approach is able to achieve state-of-the-art performance on five challenging benchmarks for domain generalization, and demonstrate its ability to deal with different types of domain shifts.
-
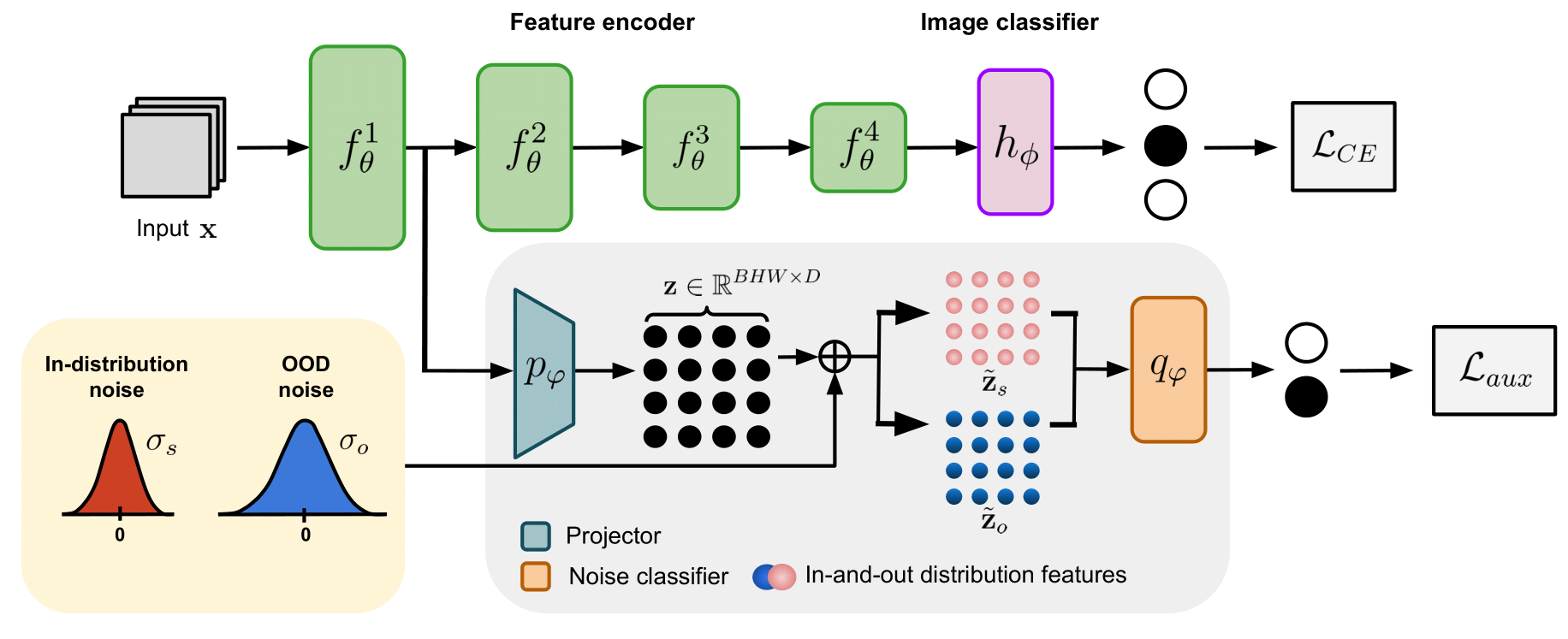 Nc-ttt: A noise constrastive approach for test-time trainingDavid Osowiechi, Gustavo Hakim, Mehrdad Noori , more authorsIn CVPR , 2024 - Highlight 🏆
Nc-ttt: A noise constrastive approach for test-time trainingDavid Osowiechi, Gustavo Hakim, Mehrdad Noori , more authorsIn CVPR , 2024 - Highlight 🏆Despite their exceptional performance in vision tasks deep learning models often struggle when faced with domain shifts during testing. Test-Time Training (TTT) methods have recently gained popularity by their ability to enhance the robustness of models through the addition of an auxiliary objective that is jointly optimized with the main task. Being strictly unsupervised this auxiliary objective is used at test time to adapt the model without any access to labels. In this work we propose Noise-Contrastive Test-Time Training (NC-TTT) a novel unsupervised TTT technique based on the discrimination of noisy feature maps. By learning to classify noisy views of projected feature maps and then adapting the model accordingly on new domains classification performance can be recovered by an important margin. Experiments on several popular test-time adaptation baselines demonstrate the advantages of our method compared to recent approaches for this task. The code can be found at: https://github.com/GustavoVargasHakim/NCTTT.git



2023
-
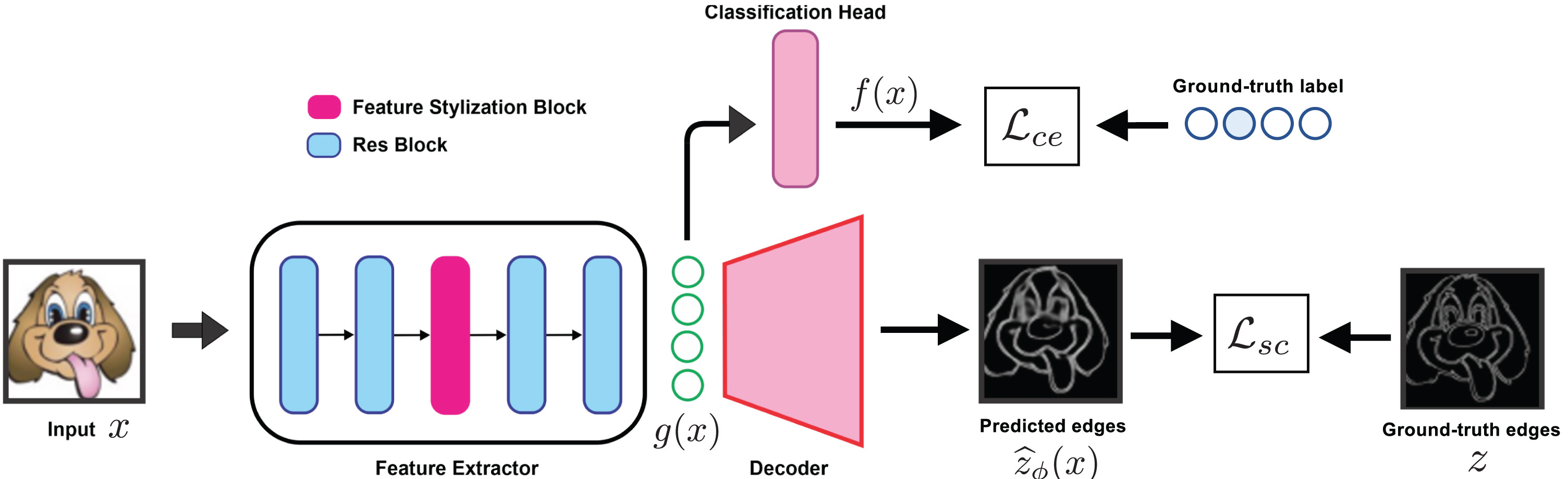 Structure-aware feature stylization for domain generalizationMilad Cheraghalikhani*, Mehrdad Noori*, David Osowiechi , more authorsComputer Vision and Image Understanding, 2023
Structure-aware feature stylization for domain generalizationMilad Cheraghalikhani*, Mehrdad Noori*, David Osowiechi , more authorsComputer Vision and Image Understanding, 2023Generalizing to out-of-distribution (OOD) data is a challenging task for existing deep learning approaches. This problem largely comes from the common but often incorrect assumption of statistical learning algorithms that the source and target data come from the same i.i.d. distribution. To tackle the limited variability of domains available during training, as well as domain shifts at test time, numerous approaches for domain generalization have focused on generating samples from new domains. Recent studies on this topic suggest that feature statistics from instances of different domains can be mixed to simulate synthesized images from a novel domain. While this simple idea achieves state-of-art results on various domain generalization benchmarks, it ignores structural information which is key to transferring knowledge across different domains. In this paper, we leverage the ability of humans to recognize objects …
-
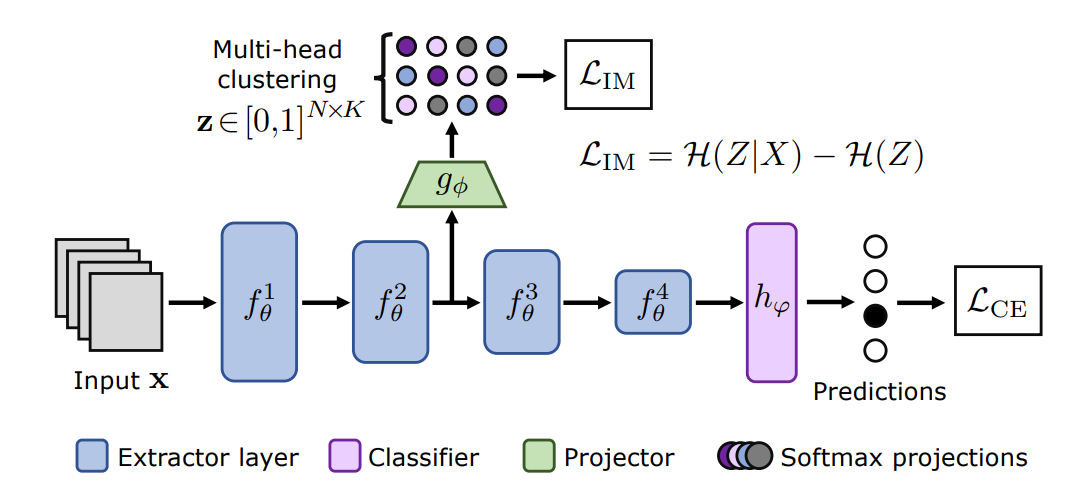 Clust3: Information invariant test-time trainingGustavo Hakim, David Osowiechi, Mehrdad Noori , more authorsIn ICCV , 2023
Clust3: Information invariant test-time trainingGustavo Hakim, David Osowiechi, Mehrdad Noori , more authorsIn ICCV , 2023Deep Learning models have shown remarkable performance in a broad range of vision tasks. However, they are often vulnerable against domain shifts at test-time. Test-time training (TTT) methods have been developed in an attempt to mitigate these vulnerabilities, where a secondary task is solved at training time simultaneously with the main task, to be later used as an self-supervised proxy task at test-time. In this work, we propose a novel unsupervised TTT technique based on the maximization of Mutual Information between multi-scale feature maps and a discrete latent representation, which can be integrated to the standard training as an auxiliary clustering task. Experimental results demonstrate competitive classification performance on different popular test-time adaptation benchmarks.
-
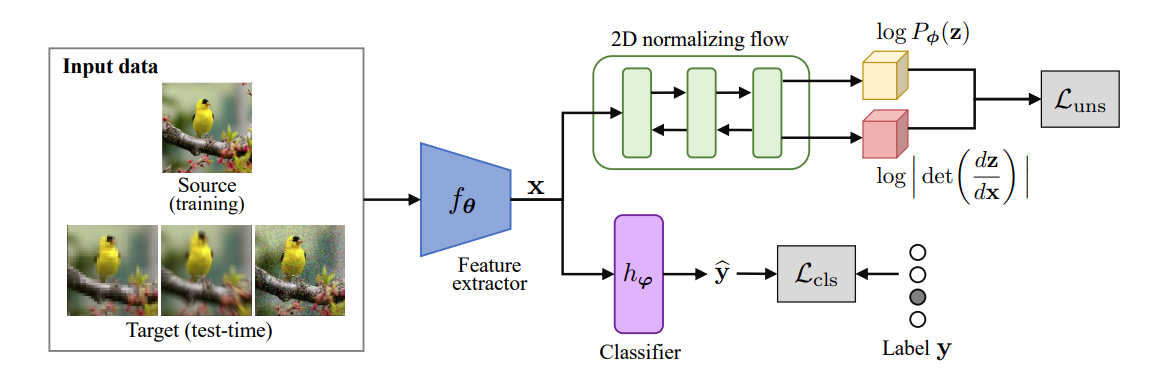 Tttflow: Unsupervised test-time training with normalizing flowDavid Osowiechi, Gustavo Hakim, Mehrdad Noori , more authorsIn WACV , 2023
Tttflow: Unsupervised test-time training with normalizing flowDavid Osowiechi, Gustavo Hakim, Mehrdad Noori , more authorsIn WACV , 2023A major problem of deep neural networks for image classification is their vulnerability to domain changes at test-time. Recent methods have proposed to address this problem with test-time training (TTT), where a two-branch model is trained to learn a main classification task and also a self-supervised task used to perform test-time adaptation. However, these techniques require defining a proxy task specific to the target application. To tackle this limitation, we propose TTTFlow: a Y-shaped architecture using an unsupervised head based on Normalizing Flows to learn the normal distribution of latent features and detect domain shifts in test examples. At inference, keeping the unsupervised head fixed, we adapt the model to domain-shifted examples by maximizing the log likelihood of the Normalizing Flow. Our results show that our method can significantly improve the accuracy with respect to previous works.



2020
-
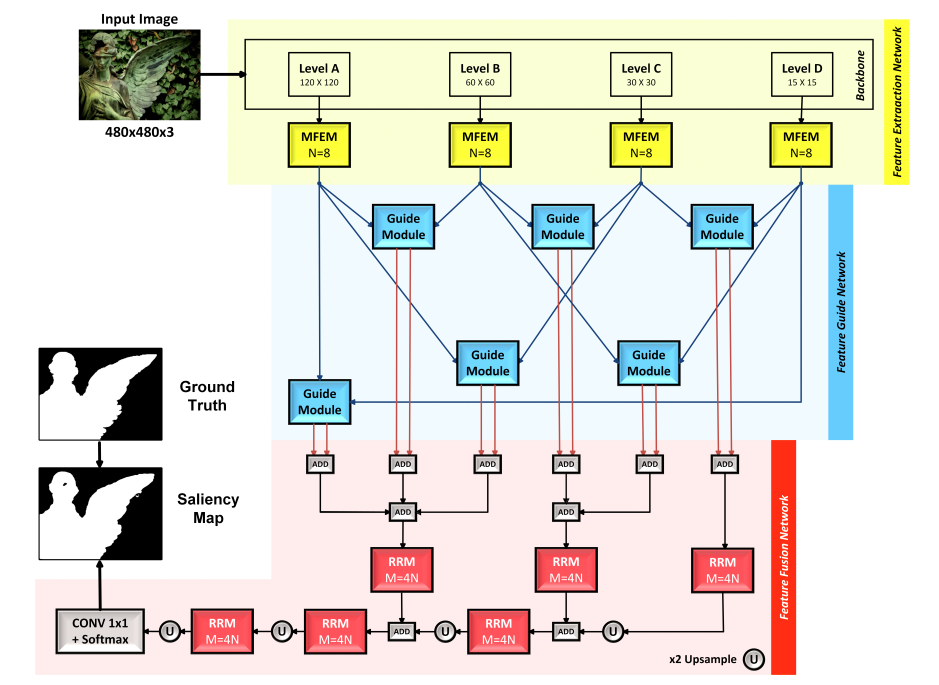 CAGNet: Content-aware guidance for salient object detectionSina Mohammadi*, Mehrdad Noori*, Ali Bahri , more authorsPattern Recognition, 2020
CAGNet: Content-aware guidance for salient object detectionSina Mohammadi*, Mehrdad Noori*, Ali Bahri , more authorsPattern Recognition, 2020Beneficial from Fully Convolutional Neural Networks (FCNs), saliency detection methods have achieved promising results. However, it is still challenging to learn effective features for detecting salient objects in complicated scenarios, in which i) non-salient regions may have “salient-like” appearance; ii) the salient objects may have different-looking regions. To handle these complex scenarios, we propose a Feature Guide Network which exploits the nature of low-level and high-level features to i) make foreground and background regions more distinct and suppress the non-salient regions which have “salient-like” appearance; ii) assign foreground label to different-looking salient regions. Furthermore, we utilize a Multi-scale Feature Extraction Module (MFEM) for each level of abstraction to obtain multi-scale contextual information. Finally, we design a loss function which outperforms the widely used Cross-entropy loss. By adopting four different pre-trained models as the backbone, we prove that our method is very general with respect to the choice of the backbone model. Experiments on six challenging datasets demonstrate that our method achieves the state-of-the-art performance in terms of different evaluation metrics. Additionally, our approach contains fewer parameters than the existing ones, does not need any post-processing, and runs fast at a real-time speed of 28 FPS when processing a 480 × 480 image.
-
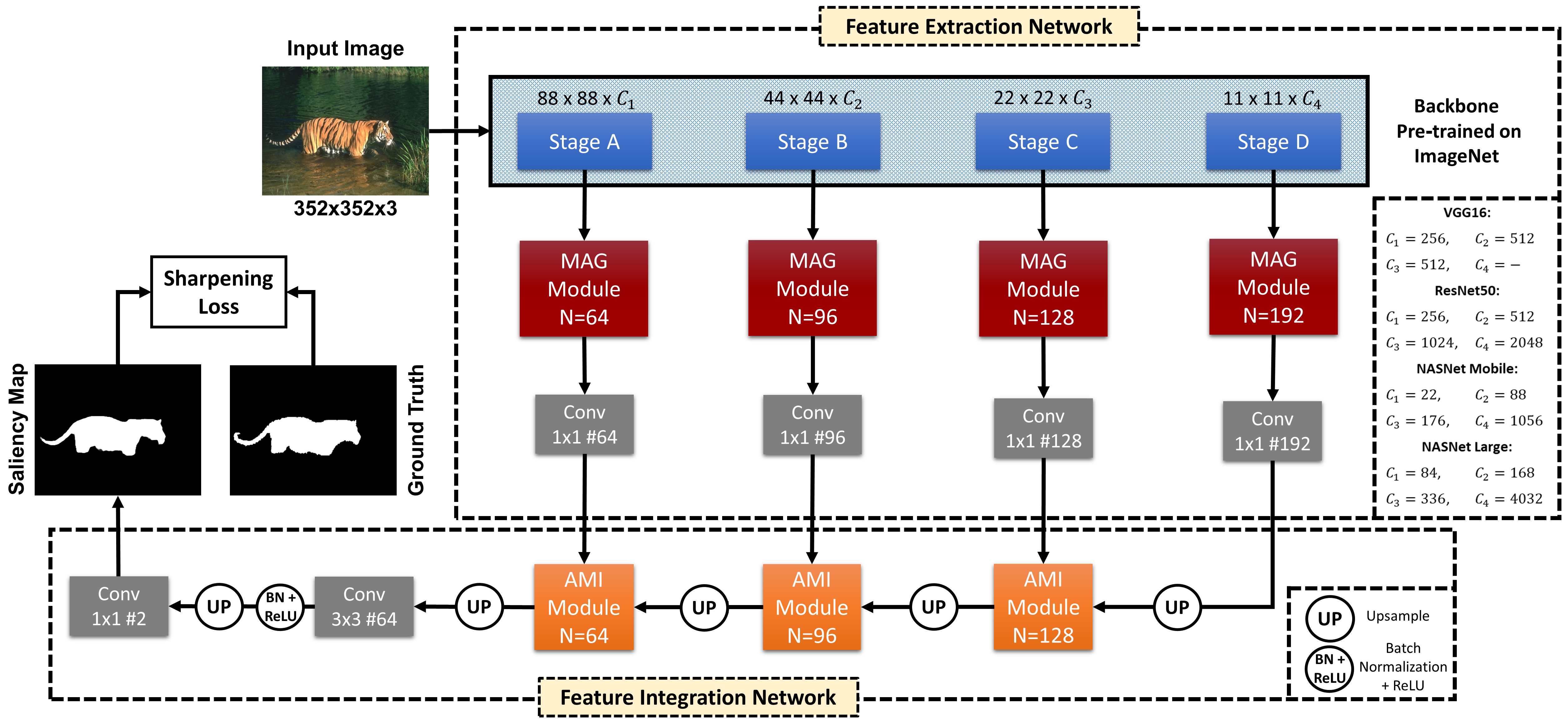 DFNet: Discriminative feature extraction and integration network for salient object detectionMehrdad Noori*, Sina Mohammadi*, Sina Ghofrani Majelan , more authorsEngineering Applications of Artificial Intelligence, 2020
DFNet: Discriminative feature extraction and integration network for salient object detectionMehrdad Noori*, Sina Mohammadi*, Sina Ghofrani Majelan , more authorsEngineering Applications of Artificial Intelligence, 2020Despite the powerful feature extraction capability of Convolutional Neural Networks, there are still some challenges in saliency detection. In this paper, we focus on two aspects of challenges: i) Since salient objects appear in various sizes, using single-scale convolution would not capture the right size. Moreover, using multi-scale convolutions without considering their importance may confuse the model. ii) Employing multi-level features helps the model use both local and global context. However, treating all features equally results in information redundancy. Therefore, there needs to be a mechanism to intelligently select which features in different levels are useful. To address the first challenge, we propose a Multi-scale Attention Guided Module. This module not only extracts multi-scale features effectively but also gives more attention to more discriminative feature maps corresponding to the scale of the salient object. To address the second challenge, we propose an Attention-based Multi-level Integrator Module to give the model the ability to assign different weights to multi-level feature maps. Furthermore, our Sharpening Loss function guides our network to output saliency maps with higher certainty and less blurry salient objects, and it has far better performance than the Cross-entropy loss. For the first time, we adopt four different backbones to show the generalization of our method. Experiments on five challenging datasets prove that our method achieves the state-of-the-art performance. Our approach is fast as well and can run at a real-time speed.


2019
-
 Remote sensing image classification via improved cross-entropy loss and transfer learning strategy based on deep convolutional neural networksAli Bahri, Sina Ghofrani Majelan, Sina Mohammadi , more authorsIEEE Geoscience and Remote Sensing Letters, 2019
Remote sensing image classification via improved cross-entropy loss and transfer learning strategy based on deep convolutional neural networksAli Bahri, Sina Ghofrani Majelan, Sina Mohammadi , more authorsIEEE Geoscience and Remote Sensing Letters, 2019Recently, deep convolutional neural networks (DCNNs) have gained great success in classifying aerial images, but in this area, the existence of the hard images, due to their innate characteristics, and weak focus of the network on them, due to the use of the cross-entropy (CE) loss, lead to reducing the accuracy of classification of aerial images. Moreover, since the last convolutional layer in a CNN has highly class-specific information, giving equal importance to all the channels causes to extract less discriminative features in comparison to weighting each of the channels adaptively. The fact that data labeling as well as creating ground truth on large data set is expensive is another point of concern in this regard. To address these problems, we have proposed a novel method for classification of aerial images. Our method includes proposing a new loss function, which enhances the focus of the network on hard examples by adding a new term to CE as a penalty term, bringing about the state-of-the-art results; designing a new multilayer perceptron (MLP) as a classifier, in which the used attention mechanism extracts more discriminative features by weighting each of the channels adaptively; and applying transfer learning strategy by adopting neural architecture search network mobile (NASNet Mobile) as a feature descriptor for the first time in the field of aerial images, which can mitigate the aforementioned costs. As indicated in the results, our proposed method outperforms the existing baseline methods and achieves state-of-the-art results on all three data sets.
-
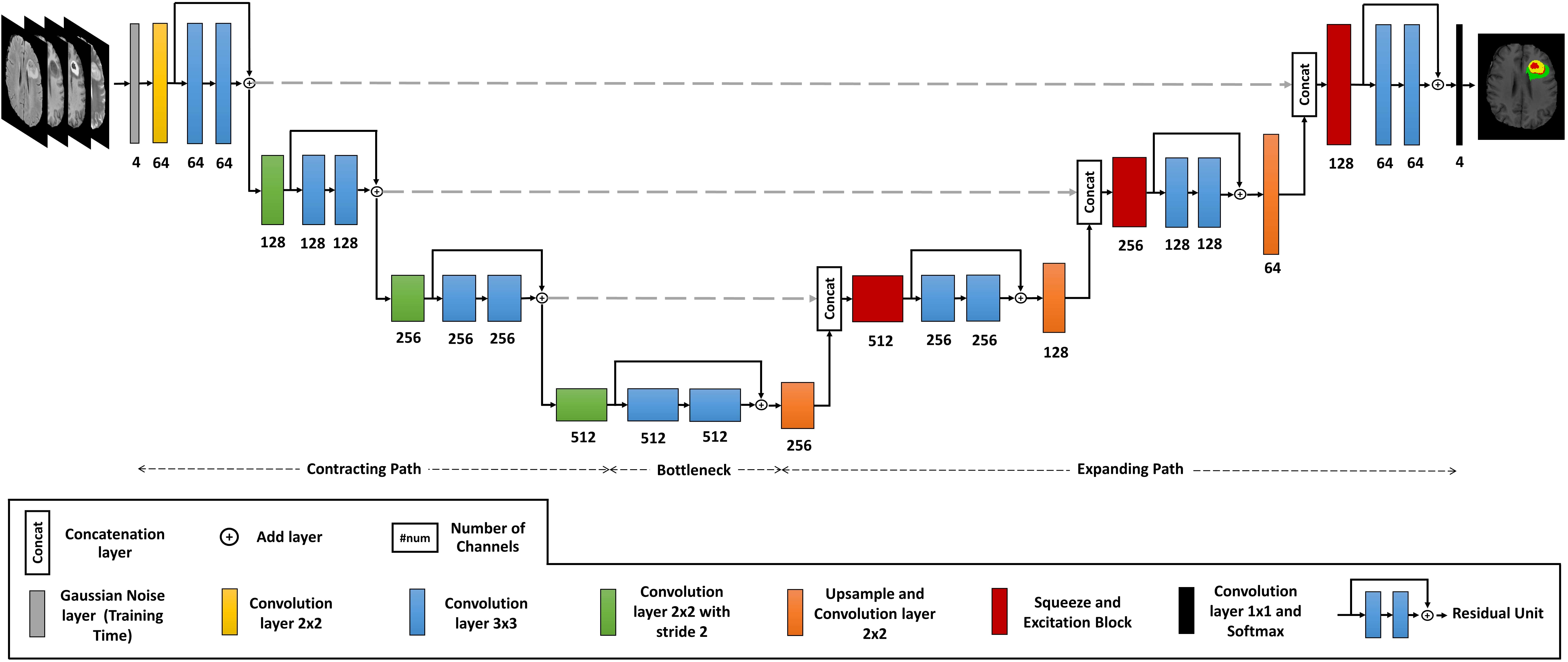 Attention-guided version of 2D UNet for automatic brain tumor segmentationMehrdad Noori, Ali Bahri, and Karim MohammadiIn ICCKE , 2019 - Best Paper 🏆
Attention-guided version of 2D UNet for automatic brain tumor segmentationMehrdad Noori, Ali Bahri, and Karim MohammadiIn ICCKE , 2019 - Best Paper 🏆Gliomas are the most common and aggressive among brain tumors, which cause a short life expectancy in their highest grade. Therefore, treatment assessment is a key stage to enhance the quality of the patients’ lives. Recently, deep convolutional neural networks (DCNNs) have achieved a remarkable performance in brain tumor segmentation, but this task is still difficult owing to high varying intensity and appearance of gliomas. Most of the existing methods, especially UNet-based networks, integrate low-level and high-level features in a naive way, which may result in confusion for the model. Moreover, most approaches employ 3D architectures to benefit from 3D contextual information of input images. These architectures contain more parameters and computational complexity than 2D architectures. On the other hand, using 2D models causes not to benefit from 3D contextual information of input images. In order to address the mentioned issues, we design a low-parameter network based on 2D UNet in which we employ two techniques. The first technique is an attention mechanism, which is adopted after concatenation of low-level and high-level features. This technique prevents confusion for the model by weighting each of the channels adaptively. The second technique is the Multi-View Fusion. By adopting this technique, we can benefit from 3D contextual information of input images despite using a 2D model. Experimental results demonstrate that our method performs favorably against 2017 and 2018 state-of-the-art methods.

